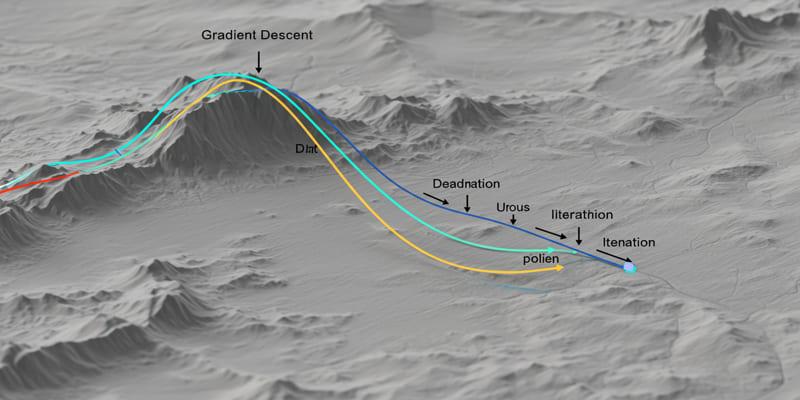
Machine learning models improve through practice, not instinct. At the core of this improvement lies a method called gradient descent—a technique used to fine-tune models by reducing their prediction errors. Rather than jumping to the right answer, models gradually update their internal settings through small, calculated steps. Think of it as walking downhill in dense fog, carefully feeling your way toward lower ground. Each move brings the model closer to better accuracy. This simple idea powers much of what we use today in modern machine learning.
How Gradient Descent Works?
Every supervised machine learning model relies on a loss function, which measures how far off predictions are from actual outcomes. For example, if a model predicts that a product costs $120 but the true cost is $100, the loss function captures this numerical prediction gap. The goal is to adjust the model gradually so it makes fewer of these mistakes. That’s where gradient descent steps in—it helps the model reduce the loss steadily with each update.
The method begins with an initial guess for the model’s parameters—these might be random values or defaults. Then, for each update, the algorithm calculates the gradient, which tells us how the loss function changes if we tweak the parameters slightly. This gradient points in the direction where the error increases fastest. But since we want to reduce error, the algorithm moves in the opposite direction—down the slope.
This movement is done repeatedly. With each step, the parameters shift slightly, and the loss typically decreases. Over time, this process helps the model settle into values that lead to better predictions. It’s like navigating a landscape of hills and valleys, always moving downward toward a low point where the model’s errors are smallest.
Types of Gradient Descent
Gradient descent comes in a few forms, each useful in different contexts. These are batch gradient descent, stochastic gradient descent, and mini-batch gradient descent.
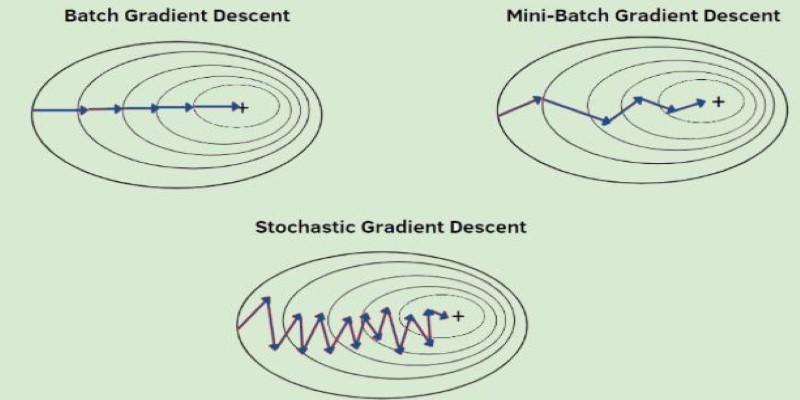
In batch gradient descent, the full dataset is used to compute each update. This gives a stable and accurate gradient but becomes slow when working with large datasets. If your data has millions of entries, calculating every single time can be inefficient.
Stochastic gradient descent (SGD) uses just one data point at a time. This makes updates faster and introduces a bit of randomness. That randomness can help the model jump out of shallow valleys or flat areas, which sometimes trap the full-batch version. However, it can also make the learning process noisier, with updates that jump around rather than move smoothly.
Mini-batch gradient descent combines both ideas. It uses small subsets of the data—called mini-batches—for each update. This makes learning faster than batch descent but more stable than SGD. It’s the most widely used method in deep learning today because it offers a good balance between speed and accuracy.
Choosing between these methods depends on the size of the data, memory limitations, and how stable or quick the updates need to be. For most real-world tasks in machine learning, a mini-batch is often the default because of its practical balance.
Learning Rate and Optimization Challenges
A major detail in gradient descent is the learning rate. This small number controls how big each step should be. If it’s too low, progress is slow and may take many steps to improve. If it’s too high, the model may overshoot the target, possibly missing the best parameter values or even making the model worse.
Tuning the learning rate is tricky. It often needs testing and adjustment depending on the problem. Some methods help by changing the learning rate as training progresses. Techniques like Adam, RMSprop, and Adagrad adapt the learning rate automatically, adjusting based on the behavior of past gradients. These methods help the model learn faster and more consistently.
Another common issue is getting stuck in local minima—low points that aren’t the lowest possible. Even more challenging are saddle points, which are flat in one direction and curved in another. These spots can slow down training or cause the model to stall. To deal with this, algorithms may use momentum, which carries some speed from earlier steps to push through flat areas or small bumps. Momentum works by remembering the previous gradient and combining it with the current one to maintain direction.
These optimization challenges are more noticeable in deep learning models, which have many parameters and complex error surfaces. Still, even basic models benefit from careful handling of the learning rate and the use of adaptive methods.
Real-World Use in Machine Learning
Gradient descent is used in nearly every model that involves learning from data. In linear regression, it helps find the best-fit line by reducing the gap between predicted and actual values. In classification problems, like spam detection or image recognition, it tunes the parameters to separate classes effectively.

In deep learning, gradient descent updates the weights of each layer in a neural network. These updates are repeated across many training cycles, known as epochs, each time bringing the model closer to a useful state. This repetitive updating makes it possible for machines to translate languages, recognize faces, and suggest products online.
For large-scale applications, gradient descent is often implemented in distributed systems. These systems divide the work across multiple processors or machines. Gradients are calculated in parallel, and parameter updates are shared to speed up training.
Even in smaller applications, gradient descent remains central. From simple linear models to complex deep networks, this approach is dependable, scalable, and flexible enough to support many tasks in modern machine learning.
Conclusion
Gradient descent is one of the most reliable techniques used in machine learning today. It helps models reduce errors step by step by adjusting internal settings in response to feedback. Its basic idea—follow the slope to reduce error—remains unchanged, even as more advanced optimizers and training tricks are developed. Whether it’s tuning a basic model or training a deep neural network, gradient descent is almost always involved. Quiet and consistent, it remains a key part of how machines learn, adapt, and improve with experience.