Machine learning thrives on data, but the type of data available often shapes the method used. With supervised learning, algorithms are trained using neatly labeled datasets, while unsupervised learning dives into raw, unlabeled data to uncover hidden patterns. Semi-supervised learning takes a position in the middle.
It is designed for situations where only a small portion of labeled data exists alongside a much larger amount of unlabeled data. This approach has become increasingly important as collecting data is easy, but labeling it is costly and time-intensive.
Understanding Semi-Supervised Learning
Semi-supervised learning is best understood as a bridge between supervised and unsupervised methods. In this setting, a model is given two types of input: a limited set of labeled data that guides learning, and a much larger pool of unlabeled data that helps the system refine its understanding. This combination is powerful because it reflects reality—datasets often exist in abundance, but most of them lack human-provided labels.
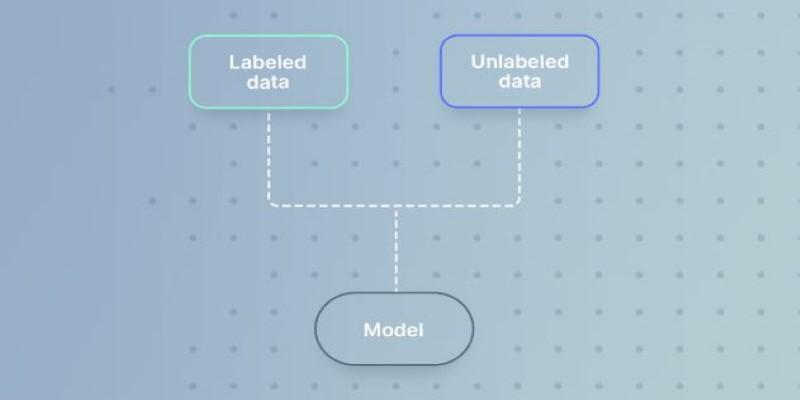
Consider a company developing a system to recognize plant diseases. Farmers or agricultural experts may provide labeled images of a few infected leaves, but tens of thousands of unlabeled photographs might remain untouched. Semi-supervised learning allows both sets to be used together. The labeled samples give the system a starting point, while the unlabeled ones expand its exposure to variations and edge cases that improve recognition accuracy. This dual use of data is what makes semi-supervised methods efficient and resource-conscious.
How Semi-Supervised Learning Works?
The core process begins with a baseline model trained on the labeled data. Once the model has enough ability to generalize, it is applied to the unlabeled portion of the dataset. At this stage, the model predicts labels for unlabeled items. Some of these predictions are taken as reliable, and they become part of a growing “pseudo-labeled” dataset. The enlarged dataset, containing both original labels and pseudo-labels, is used to retrain the model. Through repeated cycles, the system gradually improves, building on both certainty from labeled examples and structure from the unlabeled pool.
Different techniques exist to make this cycle more effective. Self-training is straightforward: the model teaches itself using its own confident predictions. Graph-based methods take a more structural approach by representing data points as nodes in a graph, linking similar examples, and spreading labels across connections. Generative models, such as those built on deep neural networks, aim to capture the overall distribution of data. By understanding how input and output are related, they can generate missing labels more reliably. Each method has strengths depending on the type of data, but they all share the idea of extracting meaningful patterns from unlabeled material.
Benefits and Limitations
Semi-supervised learning offers several benefits, particularly in domains where labeling is expensive or requires expertise. Cost efficiency is one of its strongest appeals. Instead of relying on thousands of labeled items, a few hundred may be enough to set the foundation. This makes it useful in healthcare, legal document analysis, and other fields where expert annotation is slow and costly.
Accuracy is another strength. Models trained only on small, labeled sets often struggle with overfitting, but when combined with unlabeled data, they gain exposure to broader patterns, improving generalization. The method also adapts well to changing data environments. Since unlabeled data is often continuously generated, semi-supervised systems can keep updating themselves with fresh inputs.
However, the approach is not without its limitations. The risk of error amplification is a common issue. If the initial model assigns incorrect pseudo-labels, those errors can propagate during retraining. This problem highlights the need for careful thresholds on which predictions are trusted. Another challenge lies in the assumptions made about data distribution. Many semi-supervised techniques work under the assumption that similar data points are grouped closely together, but if the dataset does not follow such a structure, the performance may decline.
Computational requirements are another consideration. While unlabeled data is cheap to gather, processing vast quantities of it demands high memory and processing power, which not every organization can afford. These challenges do not diminish the value of semi-supervised learning but show that it must be applied with care.
Applications and Future Outlook
Semi-supervised learning has made an impact across multiple areas. In natural language processing, it is applied to tasks like sentiment analysis and translation. A small dataset of annotated sentences can be combined with millions of raw texts from articles, blogs, and forums to train effective models. In computer vision, the technique is crucial for image classification, facial recognition, and medical diagnostics. Hospitals often rely on it to analyze scans and identify early signs of disease, reducing reliance on fully labeled datasets that require expert time.
Fraud detection is another practical domain. Financial institutions generate enormous streams of transaction data, but only a fraction can be labeled as fraudulent or safe. Semi-supervised systems make use of the entire stream, allowing them to detect unusual patterns that might escape fully supervised models. Online platforms also deploy these methods for spam filtering, recommendation systems, and moderation, where labeling every piece of content is impossible.
Looking ahead, the role of semi-supervised learning is expected to grow. Advances in deep learning have strengthened its effectiveness. Techniques like contrastive learning and transformer-based models have shown that unlabeled data can contribute more than previously imagined. There is also increasing interest in hybrid frameworks, where semi-supervised methods are combined with reinforcement learning or transfer learning to create more versatile systems. With data continuing to outpace labeling efforts, the demand for these approaches will only increase, making semi-supervised learning an important tool in future machine learning research and applications.
Conclusion
Semi-supervised learning strikes a balance between supervised and unsupervised methods, combining a small portion of labeled data with a much larger pool of unlabeled examples. This approach produces models that are efficient, adaptable, and capable of uncovering hidden structures within data. Techniques such as self-training, graph-based models, and generative methods all utilize unlabeled data to enhance accuracy. Although challenges such as error amplification and computational costs exist, its benefits outweigh the risks, making semi-supervised learning increasingly valuable in fields where labeled data is limited.